Chapter 5: Scraping a Live Site
Seen through the eyes of a data sleuth, almost every piece of online content is a treasure trove of information to be collected. Think of a series of Tumblr posts, or the comments for a business listed on Yelp. Every day, people who use online accounts produce an ever-growing amount of content that is displayed on websites and apps. Everything is data just waiting to be structured.
In the previous chapter, we talked about web scraping, or extracting data from HTML elements using their tags and attributes. In that chapter we scraped data from archive files we downloaded from Facebook, but in this chapter we’ll turn our attention to scraping data directly from sites that are live on the web.
Messy Data
Websites are made for people who consume them, not for people like us who want to mine them for data. For this reason, many websites have features that, while they make it easier for consumers to read and use them, may not be ideal for our data sleuthing purposes.
For instance, a Facebook post with 4,532 reactions may show an abbreviated label of 4.5K reactions. And, instead of displaying a full timestamp and data, Facebook often shows only how many hours ago a post was created. Especially on social media platforms, online content is often optimized to be helpful and interesting, but not necessarily to have complete information.
For our purposes, this means that the data we harvest can be irregular, messy, and potentially incomplete. It also means that we may need to find some ways to work around a website’s structure to grab information.
You may wonder why we would put this much work into getting data when there might be an API available. In some cases, data that is easily accessible on a live website isn’t offered through an API. Twitter, for instance, allows us to look at three months’ worth of data when scrolling through feeds, but only lets us access approximately 3,200 tweets through the API. On Facebook, data related to public groups and pages is available through the API, but it may differ from what populates our news feeds.
For one BuzzFeed News story, we analyzed 2,367 posts from the Facebook news feeds of Katherine Cooper and Lindsey Linder, a politically divided mother/daughter pair, to show them just how different their online worlds are. Cooper and Linder said that on Facebook their political differences led to heated and ugly spats, which wouldn’t occur when they talked offline. Looking at the respective feeds helped us illuminate how each woman’s information universe was shaped by whose posts appeared most frequently (see Figure 5-1).
This information was tailored to each Facebook account, meaning that it was available only through looking at Linder and Cooper’s Facebook news feeds.
Note You can read the article, “This Conservative Mom and Liberal Daughter Were Surprised by How Different Their Facebook Feeds Are,” from BuzzFeed News at https://www.buzzfeed.com/lamvo/facebook-filter-bubbles-liberal-daughter-conservative-mom/.
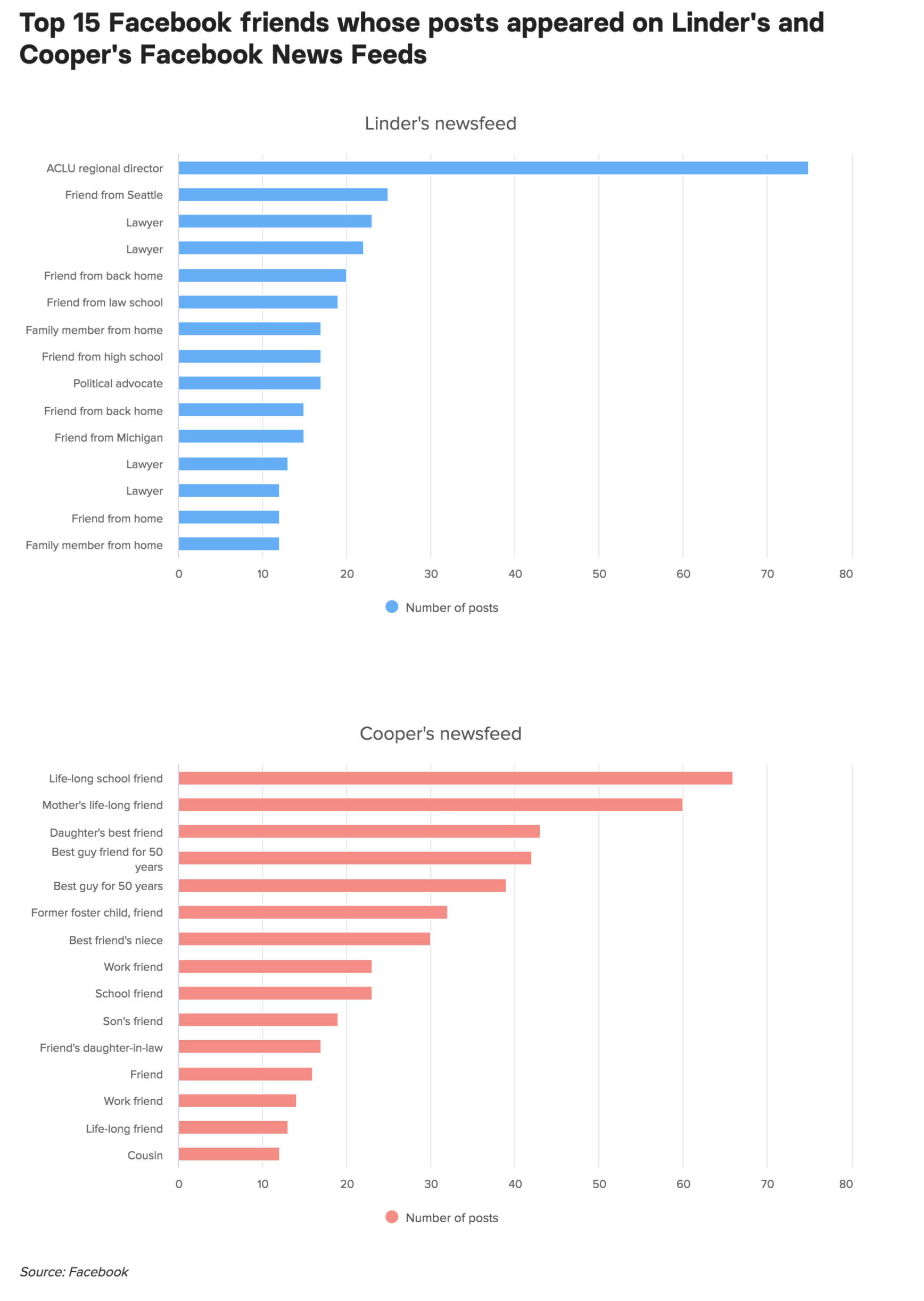
Figure 5-1: A graphic of whose posts show up the most on Linder’s and Cooper’s feeds, respectively
Ethical Considerations for Data Scraping
Social media companies set data restrictions based on what they deem appropriate for their business interests, for their users’ privacy concerns, and for other reasons. To some degree, scraping is a way around these restrictions.
The decision to scrape a website, however, should not be taken lightly. Scraping information from websites or republishing scraped data without permission may be against a company’s terms of service, and can get you banned from the platform or, worse, result in legal action.
So when is it okay to grab data from a website?
There are various considerations both for the decision to scrape data from live sites and for how we structure our web scrapers. Data journalist Roberto Rocha, in his blog post “On the Ethics of Web Scraping” (https://robertorocha.info/on-the-ethics-of-web-scraping/), listed four questions that may serve as a good guideline:
- Can I take this data?
- Can I republish this data?
- Am I overloading the website’s servers?
- What can I use this data for?
We are certainly not the first, nor will we be the last, people who have had an interest in scraping information from live websites. Given that fact, companies will likely have policies written around the practice, often in the form of two documents:
- The robots exclusion protocol
- The terms of service
Next we’ll dig deeper into both policies, starting with the robots exclusion protocol, often referred to as the robots.txt file.
The Robots Exclusion Protocol
The robots exclusion protocol is a text file that is usually hosted on the platform’s servers. You find it by typing in a website’s URL, such as http://facebook.com/, and appending robots.txt to the end, like so: http://facebook.com/robots.txt.
Many website and platform owners use this document to address web robots—programs and scripts that browse the web in automated ways, or, put more simply, that aren’t humans. These robots are often also referred to as crawlers, spiders, or, if you prefer a slightly more poetic term, web wanderers. The robots exclusion protocol file is structured in a standardized way and basically acts like a rule book for web robots that are trying to visit the website.
Not every scraper will abide by these rules. Spambots or malware may disregard the protocol, but in doing so they risk being booted from a platform. We want to make sure that we respect the rules of each website so we don’t suffer the same fate.
A very basic robots.txt file may look like this:
User-agent: *
Disallow: /
And follows this structure:
User-agent: [whom this applies to]
Disallow/Allow: [the directory or folder that should not be crawled or scraped]
The term user-agent specifies whom a rule applies to. In our example, the user-agent is *, which means that the rule applies to any robot, including one we might write. Disallow means that the robot may not crawl the directory or folder listed. In this case, the forward slash (/) specifies that the robot may not crawl anything within the root folder of the website. The root folder contains all the files of the website, meaning that this robots.txt file forbids all robots from crawling any part of the site.
This does not imply that it’s impossible to scrape data from the site. It just means the site frowns upon scraping, and doing so might get us into trouble with the site owners.
The robot.txt file can have more specific rules, too. Facebook’s robots.txt file, for instance, includes clauses that apply specifically to a user-agent named Googlebot (see Listing 5-1).
--snip--
User-agent: Googlebot
Disallow: /ajax/
Disallow: /album.php
Disallow: /checkpoint/
Disallow: /contact_importer/
Disallow: /feeds/
Disallow: /file_download.php
Disallow: /hashtag/
Disallow: /l.php
Disallow: /live/
Disallow: /moments_app/
Disallow: /p.php
Disallow: /photo.php
Disallow: /photos.php
Disallow: /sharer/
--snip--
Listing 5-1: Facebook’s more complex robots.txt file
This means that the robot named Googlebot is not allowed to access any parts of the Facebook website that include the URLs facebook.com/ajax/, facebook.com/album.php, facebook.com/checkpoint/, and so on.
The Terms of Service
A website’s terms of service document is another way to find out whether a website owner allows robots to crawl or scrape their site. Terms of service may specify what web robots are allowed to do, or how information from the website may or may not be reused.
Social media users produce data that is very valuable and important to the companies that provide these online services. Our sharing behavior, browsing, and search history allows platforms to build data profiles for users and market products to them. There’s a clear economic incentive for many social media companies to disallow others from collecting this data.
Companies also must protect a user’s data and privacy. If a spambot or other problematic robot collects user information, it may alienate the platform’s users and cause them to leave the service. For these two reasons, and various others, social media companies take their terms of service very seriously.
Technical Considerations for Data Scraping
On top of the ethical considerations around web scraping, there are also technical factors to consider. In the previous chapter, we scraped data from a web archive that we downloaded to our local machine. This means we did not use our script to connect to the internet and were not accessing live websites.
Once we do open a website using a scraper, we should consider how that could impact the server that hosts the content. Every time we open a website, we are accessing information that is hosted on a server. Each request requires the scripts of the website to fetch data, put it into HTML format, and transfer it to our browser. Each of these actions costs a tiny fraction of money—the same way transferring several megabytes of information on a mobile phone costs us money.
It’s one thing to open up a website in a browser, wait for it to load, and scroll through it the way a human user would. It’s another to program a robot to open 1,000 websites in the span of a few seconds. Imagine a server having to deal with a thousand of these transfers at one time. It might collapse under the speed and weight of these requests—in other words, the server would become overloaded.
This means that when we write a scraper or a robot, we should slow it down by instructing it to wait a few seconds between opening each website. You’ll see how to do this later in the chapter when we write our scraper.
Reasons for Scraping Data
Last but not least, it can be helpful to think about the reasons we need information. There’s no surefire way to avoid conflict with the companies that own and operate the platforms, the websites we wish to scrape, and the content that people publish, but having well-thought-out reasons for scraping can be beneficial if we decide to ask social media companies for permission to harvest data from their websites or if we decide to go ahead and scrape a site at our own risk.
Being transparent and clear about why you are scraping information can help companies decide whether to allow you to continue. For example, academics researching human rights abuses on Facebook may be able to make a better case for scraping certain Facebook profiles for noncommercial purposes, while companies republishing scraped data for a commercial service that would compete with Facebook are more likely to face legal consequences for their actions. There are myriad factors that affect what laws govern the act of scraping information—your location, the location of your company or organization, the copyright of the content that is posted, the terms of services of the platform you’re trying to scrape, the privacy issues that your data collection may raise—all of which have to be part of your decision-making process when you want to scrape information. Each case for data collection is distinct enough that you should make sure to do the legal and ethical research before you even start to write code.
Keeping in mind those ethical and technical considerations, now we’ll get started scraping data from a live website.
Scraping from a Live Website
For this example, we’ll scrape a list of women computer scientists from Wikipedia, which has a robots.txt file that allows for benign robots to scrape their content.
The URL of the page we’ll scrape, shown in Figure 5-2, is https://en.wikipedia.org/wiki/Category:Women_computer_scientists.
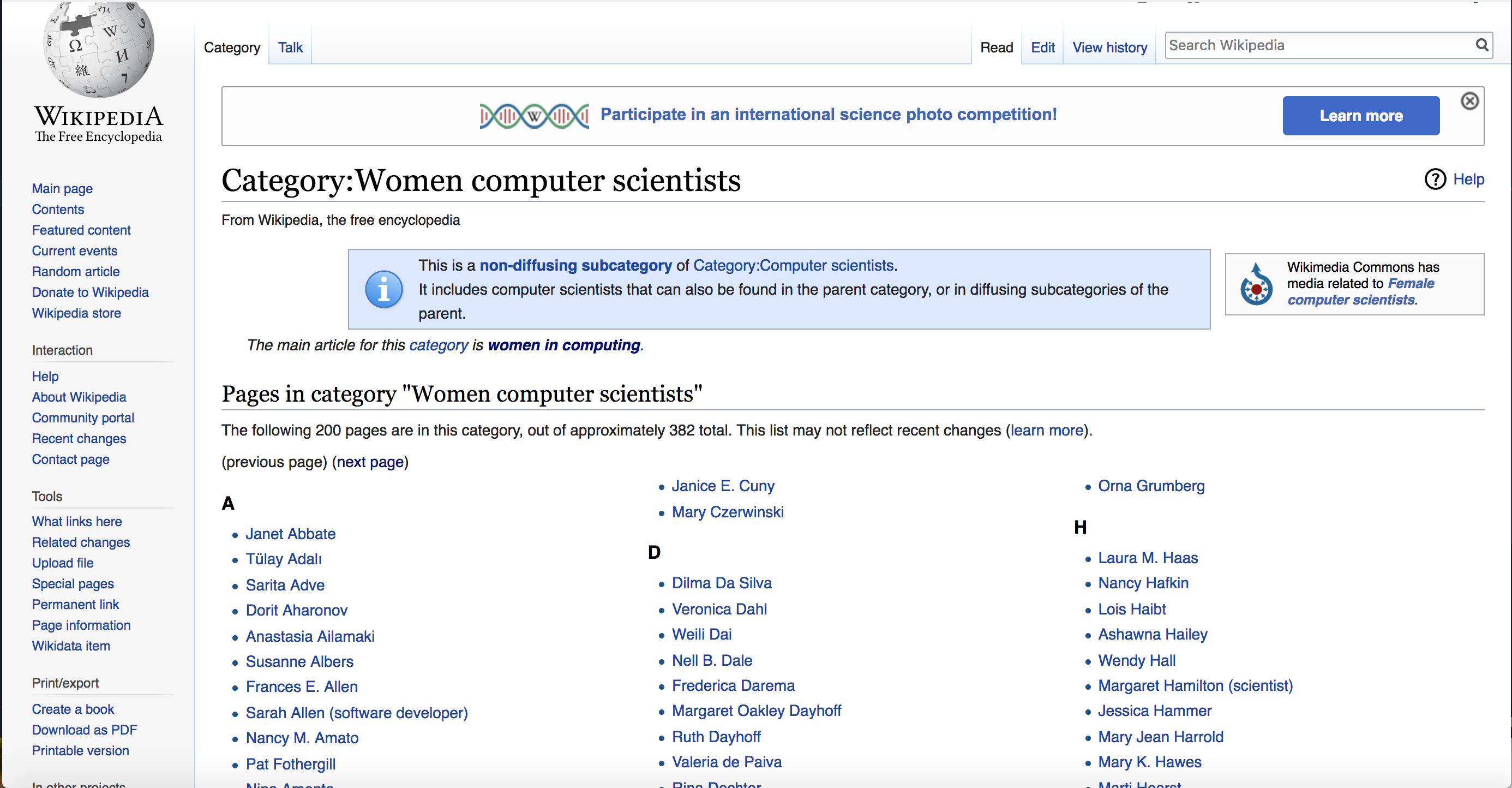
Figure 5-2: Wikipedia’s list of women computer scientists
As we did in previous chapters, we begin our script by loading all the libraries we need. Open your text editor and save a new file called wikipediascraper.py in a folder you can easily access. Then enter the code from Listing 5-2 into that file.
# Import our modules or packages that we will need to scrape a website
import csv
from bs4 import BeautifulSoup
import requests
# make an empty array for your data
rows = []
Listing 5-2: Setting up the script
We import the csv, requests, and beautifulsoup4 libraries, which we used in previous chapters. Up next, as we did in our previous script, we assign the variable rows the value of an empty list, to which we’ll add our rows of data later.
Then comes a slightly new task: opening up a live website. Again, the process is very similar to what we did in Chapter 2 when we opened an API feed based on a URL, but this time we’ll open up the Wikipedia page that contains the information we want to harvest. Enter the code from Listing 5-3 into your Python file.
# open the website
url = "https://en.wikipedia.org/wiki/Category:Women_computer_scientists"①
page = requests.get(url)②
page_content = page.content③
# parse the page with the Beautiful Soup library
soup = BeautifulSoup(page_content, "html.parser")
Listing 5-3: Retrieving content from the URL
The first variable we set, url ①, is a string that contains the URL we want to open with our script. Then we set the variable page ② to contain the HTML page, which we open using the requests library’s get() function; this function grabs the site from the web. After that, we use the content ③ property from requests to encode the HTML of the page we just opened and ingested in the previous line as bytes that are interpretable by Beautiful Soup. Then we use Beautiful Soup’s HTML parser to help our script differentiate between HTML and the site’s content.
Analyzing the Page’s Contents
Just as we did with the HTML pages of our Facebook archives, we need to analyze the HTML tags that contain the content we want to harvest through our Python script.
As before, the Web Inspector is a helpful tool that allows us to isolate the relevant code. In this case, we want a list of women computer scientists that was assembled by Wikipedia writers and editors, which we can see in Figure 5-3.
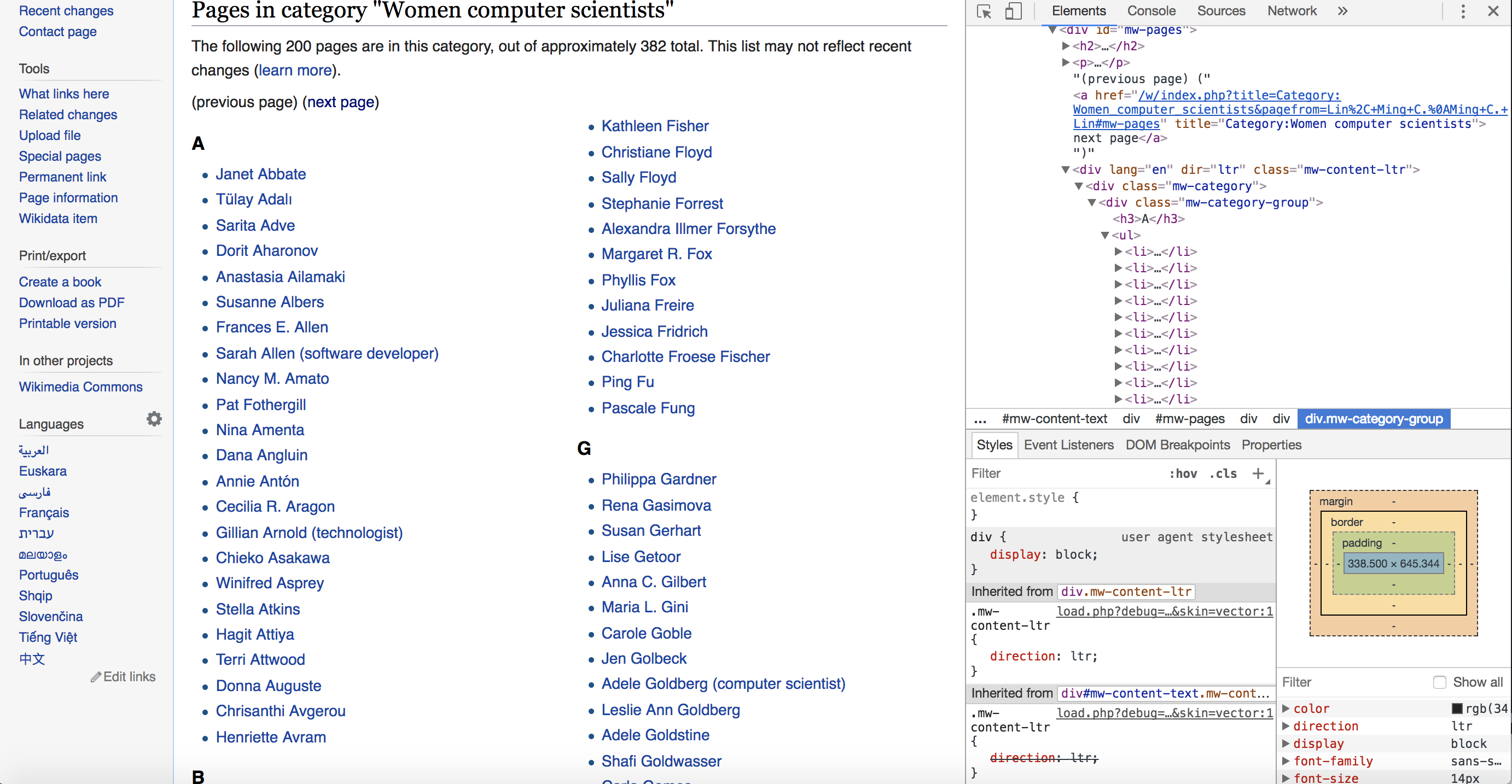
Figure 5-3: The Wikipedia page we want to scrape, shown with the Web Inspector open
As you can see on the page, the computer scientists’ names are subdivided into lists sorted by each woman’s last name and displayed in alphabetical order. In addition to that, our lists are spread onto two pages. We can access the second page by clicking a next page link.
To reveal which elements contain our content, we can right-click a name on the list we want to scrape and access the HTML of the page. Remember we’re interested in detecting patterns that we can take advantage of when collecting our data.
Right-click on a name in the “A” group and select the option in the drop-down menu that says “Inspect.” This should change the view inside the Web Inspector: the HTML view should jump to the part of the code that contains the name in the “A” group that you selected and highlight the tag that contains it. Websites can be very long and contain hundreds of HTML tags, and Inspect allows you to locate a specific element you see on the page in the HTML of the website. You can think of it as the “You Are Here” marker on a map.
Now that you have located where one of the names in the “A” group is located in the HTML, you can start examining the HTML tag structure that contains all the other names in the “A” group a little closer. You can do that by scrolling through the code until you reach the parent <div> tag, <div class="mw-category-group">, which highlights the corresponding section of the page, as shown in Figure 5-4. This tag holds the list of last names beginning with “A.”
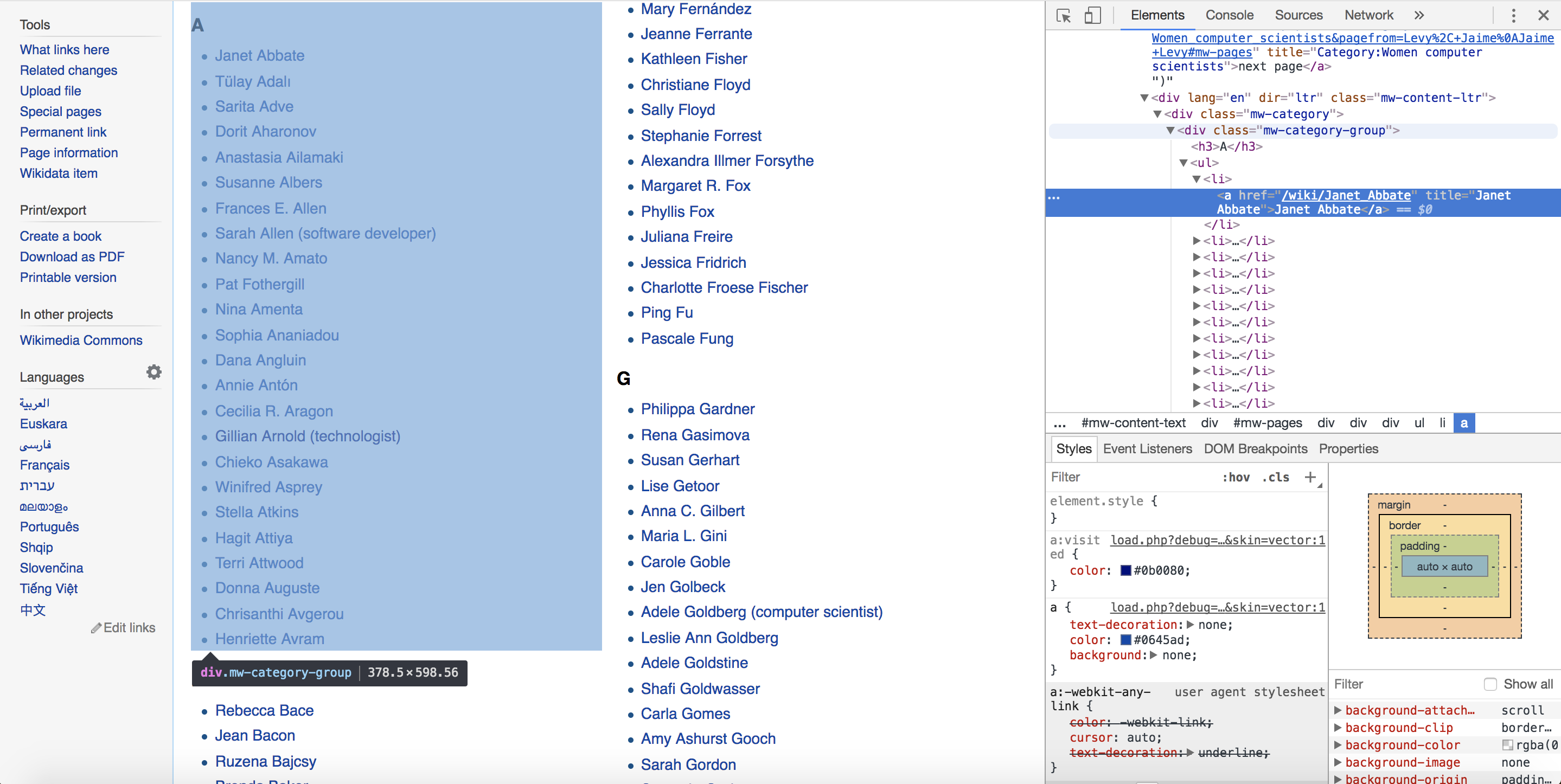
Figure 5-4: The parent tag of the list of women computer scientists filed under the highlighted letter “A”
Now right-click the parent tag and choose Edit as HTML. This should allow you to copy and paste the parent tag and every HTML tag that is nested inside the parent tag, as shown in Figure 5-5.
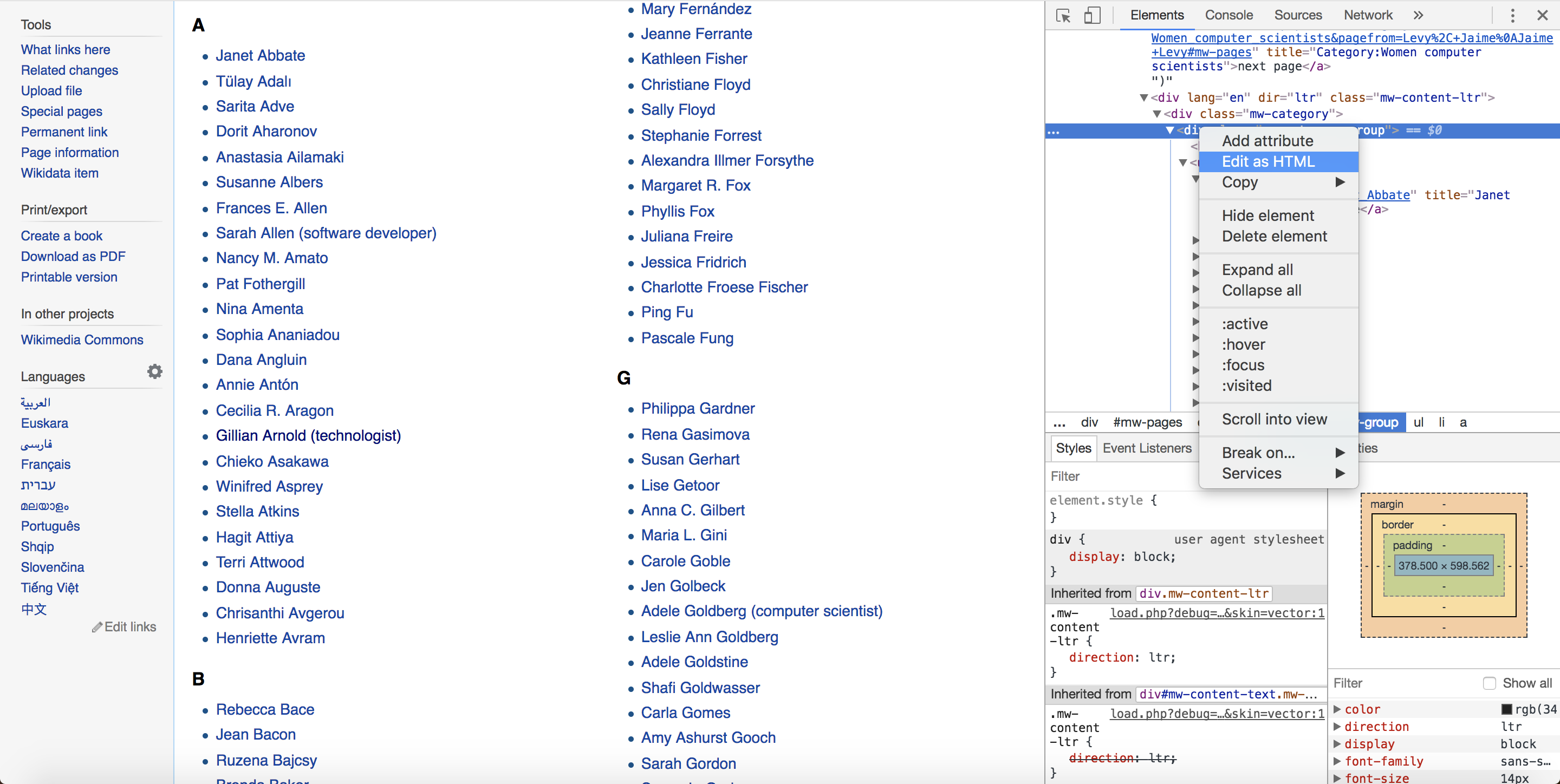
Figure 5-5: Selecting Edit as HTML
If you paste the code we just copied into an empty file in your text editor, it should look like Listing 5-4.
<div class="mw-category-group"><h3>A</h3>
<ul><li><a href="/wiki/Janet_Abbate" title="Janet Abbate">Janet Abbate</a></li>
<li><a href="/wiki/T%C3%BClay_Adal%C4%B1" title="Tülay Adalı">Tülay Adalı</a></li>
<li><a href="/wiki/Sarita_Adve" title="Sarita Adve">Sarita Adve</a></li>
<li><a href="/wiki/Dorit_Aharonov" title="Dorit Aharonov">Dorit Aharonov</a></li>
<li><a href="/wiki/Anastasia_Ailamaki" title="Anastasia Ailamaki">Anastasia Ailamaki</a></li>
<li><a href="/wiki/Susanne_Albers" title="Susanne Albers">Susanne Albers</a></li>
<li><a href="/wiki/Frances_E._Allen" title="Frances E. Allen">Frances E. Allen</a></li>
<li><a href="/wiki/Sarah_Allen_(software_developer)" title="Sarah Allen (software developer)">Sarah Allen (software developer)</a></li>
<li><a href="/wiki/Nancy_M._Amato" title="Nancy M. Amato">Nancy M. Amato</a></li>
<li><a href="/wiki/Pat_Fothergill" title="Pat Fothergill">Pat Fothergill</a></li>
<li><a href="/wiki/Nina_Amenta" title="Nina Amenta">Nina Amenta</a></li>
<li><a href="/wiki/Dana_Angluin" title="Dana Angluin">Dana Angluin</a></li>
<li><a href="/wiki/Annie_Ant%C3%B3n" title="Annie Antón">Annie Antón</a></li>
<li><a href="/wiki/Cecilia_R._Aragon" title="Cecilia R. Aragon">Cecilia R. Aragon</a></li>
<li><a href="/wiki/Gillian_Arnold_(technologist)" title="Gillian Arnold (technologist)">Gillian Arnold (technologist)</a></li>
<li><a href="/wiki/Chieko_Asakawa" title="Chieko Asakawa">Chieko Asakawa</a></li>
<li><a href="/wiki/Winifred_Asprey" title="Winifred Asprey">Winifred Asprey</a></li>
<li><a href="/wiki/Stella_Atkins" title="Stella Atkins">Stella Atkins</a></li>
<li><a href="/wiki/Hagit_Attiya" title="Hagit Attiya">Hagit Attiya</a></li>
<li><a href="/wiki/Terri_Attwood" title="Terri Attwood">Terri Attwood</a></li>
<li><a href="/wiki/Donna_Auguste" title="Donna Auguste">Donna Auguste</a></li>
<li><a href="/wiki/Chrisanthi_Avgerou" title="Chrisanthi Avgerou">Chrisanthi Avgerou</a></li>
<li><a href="/wiki/Henriette_Avram" title="Henriette Avram">Henriette Avram</a></li></ul></div>
Listing 5-4: The Wikipedia HTML without indentation
As you can see here, the HTML code on websites is often rendered with little to no indentation or spaces. That’s because the browser reads code from top to bottom and each line from left to right. The fewer spaces there are between different lines of code, the faster the browser can read them.
However, this pared-down code is much harder for humans to read than indented code. Using spaces and tabs allows coders to indicate hierarchies and nesting within different parts of the code. Since most web pages minify, or minimize, code to cater to browsers, we sometimes need to unminify it. It will be much easier for us to read and understand the hierarchy and patterns of the HTML elements that contain our desired information if this code is indented.
There are plenty of free tools on the web that reintroduce indentation and spaces to minified code, including Unminify (http://unminify.com/). To use these tools, you often just need to copy the minified HTML, paste it into a window that the tool provides, and click a button to unminify it!
Listing 5-5 shows the same code from Listing 5-4, now unminified.
<div class="mw-category-group">①
<h3>A</h3>②
<ul>③
④ <li><a href="/wiki/Janet_Abbate" title="Janet Abbate"⑤>Janet Abbate</a></li>
<li><a href="/wiki/T%C3%BClay_Adal%C4%B1" title="Tülay Adalı">Tülay Adalı</a></li>
<li><a href="/wiki/Sarita_Adve" title="Sarita Adve">Sarita Adve</a></li>
<li><a href="/wiki/Dorit_Aharonov" title="Dorit Aharonov">Dorit Aharonov</a></li>
<li><a href="/wiki/Anastasia_Ailamaki" title="Anastasia Ailamaki">Anastasia Ailamaki</a></li>
<li><a href="/wiki/Susanne_Albers" title="Susanne Albers">Susanne Albers</a></li>
<li><a href="/wiki/Frances_E._Allen" title="Frances E. Allen">Frances E. Allen</a></li>
<li><a href="/wiki/Sarah_Allen_(software_developer)" title="Sarah Allen (software developer)">Sarah Allen (software developer)</a></li>
<li><a href="/wiki/Nancy_M._Amato" title="Nancy M. Amato">Nancy M. Amato</a></li>
<li><a href="/wiki/Pat_Fothergill" title="Pat Fothergill">Pat Fothergill</a></li>
<li><a href="/wiki/Nina_Amenta" title="Nina Amenta">Nina Amenta</a></li>
<li><a href="/wiki/Dana_Angluin" title="Dana Angluin">Dana Angluin</a></li>
<li><a href="/wiki/Annie_Ant%C3%B3n" title="Annie Antón">Annie Antón</a></li>
<li><a href="/wiki/Cecilia_R._Aragon" title="Cecilia R. Aragon">Cecilia R. Aragon</a></li>
<li><a href="/wiki/Gillian_Arnold_(technologist)" title="Gillian Arnold (technologist)">Gillian Arnold (technologist)</a></li>
<li><a href="/wiki/Chieko_Asakawa" title="Chieko Asakawa">Chieko Asakawa</a></li>
<li><a href="/wiki/Winifred_Asprey" title="Winifred Asprey">Winifred Asprey</a></li>
<li><a href="/wiki/Stella_Atkins" title="Stella Atkins">Stella Atkins</a></li>
<li><a href="/wiki/Hagit_Attiya" title="Hagit Attiya">Hagit Attiya</a></li>
<li><a href="/wiki/Terri_Attwood" title="Terri Attwood">Terri Attwood</a></li>
<li><a href="/wiki/Donna_Auguste" title="Donna Auguste">Donna Auguste</a></li>
<li><a href="/wiki/Chrisanthi_Avgerou" title="Chrisanthi Avgerou">Chrisanthi Avgerou</a></li>
<li><a href="/wiki/Henriette_Avram" title="Henriette Avram">Henriette Avram</a></li>
</ul>
</div>
Listing 5-5: The Wikipedia code with indentation
As you can see, the content of the HTML page contains the parent <div> tag with the class mw-category-group ①, a headline inside an <h3> tag ② containing a letter of the alphabet, an unordered list in a <ul> tag ③, and <li> tags ④ inside that list that contain all the women whose last names start with the letter specified in the <h3> heading—in this case, A. There are also links to each woman’s Wikipedia page associated with each name and <li> tag ⑤.
Storing the Page Content in Variables
Given what we know now about the code, let’s recap what we have to do after opening the page:
- Grab every unordered list of names from the first page.
- Extract information from each list item, including the name of the woman computer scientist, the link to her profile, and the letter she is categorized under.
- Create a row of data based on this information and write each row into a .csv file.
To help us visualize what this data set may look like and how we would organize it, the spreadsheet in Figure 5-6 structures our data based on our instructions.
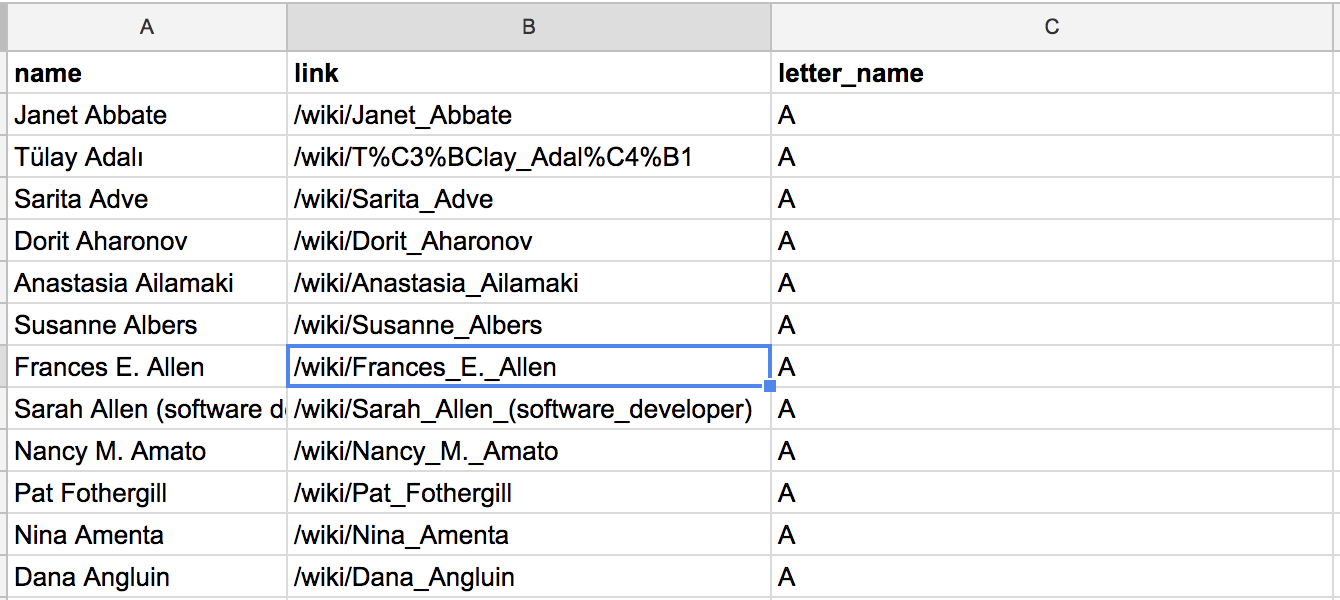 Figure 5-6: A mockup spreadsheet that can help us structure our scraper
Figure 5-6: A mockup spreadsheet that can help us structure our scraper
Okay, now we’re ready to begin writing the part of our script that grabs information from our HTML!
We’ll start by grabbing every alphabetical list with our script. Go back to your Python file and enter the code in Listing 5-6.
--snip--
soup = BeautifulSoup(page_content, "html.parser")
content = soup.find("div", class_="mw-category")①
all_groupings = content.find_all("div", class_="mw-category-group")②
Listing 5-6: Using Beautiful Soup to retrieve the HTML
In this code, we use the find() ① function to find a <div> tag that contains the class mw-category. This is the overall <div> tag that contains the content we want to scrape, as we saw earlier when looking at our page through the Web Inspector. We’ll assign this value—meaning that entire HTML block containing all the lists—to the variable content. The next line puts all the <div> tags containing the class mw-category-group ② into the variable all_groupings. This task is best accomplished using the function find_all(), which searches the HTML for elements based on characteristics that we specify and creates a list of them for us. We pass the find_all() function two arguments: the string “div”, which tells find_all() what kind of HTML element we want it to find, and the class_ argument "mw-category-group". This means that the find_all() function will fetch every <div> that has the class "mw-category-group" and create a list of them. The variable all_groupings, then, will hold a list of HTML elements that contains a list of names sorted alphabetically, as well as the first letter of each woman’s last name.
Up next, we need to cycle through each alphabetical list and collect the names from each one, as shown in Listing 5-7. Enter this code into your Python file as well.
--snip--
all_groupings = content.find_all("div", class_="mw-category-group")
for grouping in all_groupings:①
names_list = grouping.find("ul")②
category = grouping.find("h3").get_text()③
alphabetical_names = names_list.find_all("li")④
Listing 5-7: Collecting each name using a for loop
First we need to write a for loop ① to go through each of the groupings we just added to our variable all_groupings. Then we gather the unordered list tag <ul> ② inside each alphabetical list using the grouping.find() function and put all the lists inside a variable we’ve defined, names_list. Next, we gather the headline tag <h3> using the grouping.find() function again ③. The code grouping.find("h3") contains all the <h3> headlines, but all we need for the purposes of our .csv file is the text associated with each headline. To gather the text, we use the get_text() function to extract the letter belonging to each group. We can do all of this in one line and store the results in the variable category. Last but not least, we grab every single list item tag <li> inside the <ul> unordered lists. Since we stored all the <ul> groupings in names_list, we can simply use the find_all() function directly on the variable ④. This should allow us to get the letter and a list of all associated names.
The last step of the script is to create a row of information that contains the name, the link, and the letter connected to each name, as shown in Listing 5-8.
--snip--
category = grouping.find("h3").get_text()
alphabetical_names = names_list.find_all("li")
for alphabetical_name in alphabetical_names:①
# get the name
name = alphabetical_name.text②
# get the link
anchortag = alphabetical_name.find("a",href = True)③
link = anchortag["href"]④
# get the letter
letter_name = category
Listing 5-8: Assigning each name’s information to variables to prepare for creating a row in a .csv file
This is perhaps the first time our code gets a little more complicated: we need to write a loop inside another loop! First we had to loop through each alphabetical list. In the code in Listing 5-8, we are now writing another for loop ① inside the loop we wrote in Listing 5-7—very meta! In Listing 5-8’s nested loop, we cycle through every alphabetical name within the list of list item tags <li> that is currently stored in the variable alphabetical_names.
Each <li> list item tag contains a name, which we extract using the text attribute ②. This list item also contains links, which we grab using two other functions. To grab the anchor tag <a>, we use the find() function ③. The find() function has two parameters. The first parameter is the tag we want to find, which is simply “a” for the anchor tag. The second parameter is optional, meaning that we don’t always have to pass an argument to it. Optional parameters have a default value that we can change when needed. In this case, the optional parameter is href, which is usually set to the value False by default. By setting href = True, we tell the function to grab an anchor tag only if the tag has an href attribute, or link, associated with it. Otherwise—that is, if we don’t pass the optional parameter an argument—the find() function will grab every anchor tag by default.
We store the anchor tag we retrieve inside the variable anchortag, which now would contain all the information from the anchor tag we retrieved. We want to get the link inside the anchor tag, so we need to access the tag’s href value, which is stored in the tag as an attribute. We do this by grabbing the href attribute using brackets containing the string "href" ④. Afterward, as we did in the previous chapter, we create a dictionary that we can use to structure the data we gather, as shown in Listing 5-9.
--snip--
# make a dictionary that will be written into the csv
row = {"name": name,①
"link": link,②
"letter_name": letter_name}③
rows.append(row)④
Listing 5-9: Creating a dictionary to store data
We’ll create one row of data every time the for loop iterates. In the first line of code, we assign the variable row a dictionary, using braces that we open in line ① and close in line ③. Then we proceed to assign each key (name ①, link ②, and letter_name ③) the value that holds the corresponding data we gathered earlier in the script. In the end, we append the row of data to our list variable rows ④.
The script you have written thus far should look like Listing 5-10.
# Import our modules or packages that we will need to scrape a website
import csv
from bs4 import BeautifulSoup
import requests
# make an empty list for your data
rows = []
# open the website
url = "https://en.wikipedia.org/wiki/Category:Women_computer_scientists"
page = requests.get(url)
page_content = page.content
# parse the page through the BeautifulSoup library
soup = BeautifulSoup(page_content, "html.parser")
content = soup.find("div", class_="mw-category")
all_groupings = content.find_all("div", class_="mw-category-group")
for grouping in all_groupings:
names_list = grouping.find("ul")
category = grouping.find("h3").get_text()
alphabetical_names = names_list.find_all("li")
for alphabetical_name in alphabetical_names:
# get the name
name = alphabetical_name.text
# get the link
anchortag = alphabetical_name.find("a",href=True)
link = anchortag["href"]
# get the letter
letter_name = category
# make a data dictionary that will be written into the csv
row = { "name": name,
"link": link,
"letter_name": letter_name}
rows.append(row)
Listing 5-10: The entire script you have written so far
This script works great it you want to gather data only from one page, but it’s not as useful if you need to collect data from dozens or even hundreds of pages. Remember how I keep emphasizing that we should write reusable code? We finally have a use case for this in our exercise!
Making the Script Reusable
We now have a script that will grab the names of every woman computer scientist on a single page. But the page contains only half of the names, because there are so many significant women computer scientists that Wikipedia had to divide the list into two web pages.
This means, to get the complete list, we need to grab the rest of the names from the next page. We can do this by wrapping all the code we just wrote into a function that we can reuse, like the one shown in Listing 5-11.
# Import our modules or packages that we will need to scrape a website
import csv
from bs4 import BeautifulSoup
import requests
# make an empty list for your data
rows = []
① def scrape_content(url):
② page = requests.get(url)
page_content = page.content
# parse the page through the BeautifulSoup library
soup = BeautifulSoup(page_content, "html.parser")
content = soup.find("div", class_="mw-category")
all_groupings = content.find_all("div", class_="mw-category-group")
for grouping in all_groupings:
names_list = grouping.find("ul")
category = grouping.find("h3").get_text()
alphabetical_names = names_list.find_all("li")
for alphabetical_name in alphabetical_names:
# get the name
name = alphabetical_name.text
# get the link
anchortag = alphabetical_name.find("a",href=True)
link = anchortag["href"]
# get the letter
letter_name = category
# make a data dictionary that will be written into the csv
row = { "name": name,
"link": link,
"letter_name": letter_name}
rows.append(row)
Listing 5-11: Putting the script into a function for reuse
To reproduce Listing 5-11 in your own file, first remove the following line of code from your current script:
url = "https://en.wikipedia.org/wiki/Category:Women_computer_scientists"
You no longer need to assign the url variable a value because we need to run the code on multiple URLs.
Next, at ①, we tell Python that we’re creating a function called scrape_content() that takes the argument url. Then we add the rest of the code at ② that makes up the contents of the scrape_content() function. All of the code in the function is the same as the code you wrote in Listing 5-10, except now it is indented. (If the code editor that you’re using didn’t automatically indent your code, you can usually highlight every line of code you want to include in your function and press tab.) You’ll notice that at ②, we open a URL using the requests.get(url) function. The url variable in the function refers to the url at ①.
In plain English, we just gave Python an instruction manual for all the things we want to do when we call the function scrape_content(url). We’ll replace the url argument with an actual URL that we want our script to open and scrape. For example, to run the function on the Wikipedia page, we just add the following line to our script:
scrape_content("<https://en.wikipedia.org/wiki/Category:Women_computer_scientists>")
However, we need to run the function multiple times. If we want to run it on one or two URLs, this works great, but we’ll likely need to run it on hundreds of URLs. To run it for more than one URL, we can create a list that contains each URL as a string; that way, we can loop through the list to run the function for each link. To do this, add the code in Listing 5-12 to your script after the code from Listing 5-11.
# open the website
urls = ①["https://en.wikipedia.org/wiki/Category:Women_computer_scientists", "https://en.wikipedia.org/w/index.php?title=Category:Women_computer_scientists&pagefrom=Lin%2C+Ming+C.%0AMing+C.+Lin#mw-pages"]
def scrape_content(url):
--snip--
rows.append(row)
for url in urls:②
scrape_content(url)③
Listing 5-12: Running the function on URLs using a loop
The variable urls ① holds a list of two strings: the URL of the first Wikipedia page, which holds the first half of the names of women computer scientists, and then the link for the second page that holds the rest of the names. Then we write a for loop that cycles through every URL in our urls list ② and runs the scrape_content() function ③ for each URL. If you wanted to run the scraper on more Wikipedia list pages, you would simply add those as links to the urls list.
Now that we have put all our data into our rows variable, it’s time for us to output our data as a spreadsheet. Add the lines of code in Listing 5-13 to your script, which will do the job.
--snip--
# make a new csv into which we will write all the rows
with open("all-women-computer-scientists.csv", "w+") as csvfile:①
# these are the header names:
fieldnames = ["name", "link", "letter_name"]②
# this creates your csv
writer = csv.DictWriter(csvfile, fieldnames=fieldnames)③
# this writes in the first row, which are the headers
writer.writeheader()④
# this loops through your rows (the array you set at the beginning and have updated throughtout)
for row in rows:⑤
# this takes each row and writes it into your csv
writer.writerow(row)⑥
Listing 5-13: Create a .csv file from the collected data
As we did before, we use the with open() as csvfile ① statement to create and open an empty .csv file called all-women-computer-scientists.csv. Since we’re using a dictionary to gather our data, we need to specify a list of header names for our spreadsheet ② and then use the DictWriter() function from the csv library ③ to write each header into the first row ④.
Finally, we need to loop through each row that we compiled in the rows list ⑤ and write each row into our spreadsheet ⑥.
Practicing Polite Scraping
Almost done! We have now written a working script that can gather data efficiently. But there are two things that we should consider adding to the script both to be transparent about our efforts and to avoid overloading the servers that host the data we want to scrape.
First, it’s always helpful to provide contact details for your scraper so the owner of the website you’re scraping can contact you if any issues arise. In some cases, if your scraper is causing trouble, you may be booted from a website. If a website owner has the ability to contact you and tell you to adjust your scraper, however, you’re more likely to be able to continue your work on the site.
The Python library we installed for this scraper, requests, comes with a helpful parameter called headers, which we can set whenever we access a page from the web. We can use it to create a data dictionary to hold information that is important for the website owner to know. Add the code from Listing 5-14 to your scraper, substituting your own information for mine.
--snip--
headers = {①"user-agent" : "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3325.162 Safari/537.36",
② "from": "Your name example@domain.com"}
--snip--
page = requests.get(url, headers=headers)③
Listing 5-14: Adding headers to your scraper
The code from Listing 5-14 has to be placed after the first few lines of our script where we import the libraries, since we need to load the requests library before we can leverage it. Since the headers are variables you set up and won’t change throughout the script, you can place them near the top of your script, ideally right after the import lines. The line that calls up the page we want to scrape, page = requests.get(url, headers=headers), is a modification of a line you’ve already written. Replace the line that currently reads page = requests.get(url) with the new page calling code. This alerts the website owner of your information each time you request to load the URL of the website you want to scrape.
The information assigned to the headers variable is information you exchange with a server when you open a URL through a script. As you can see, all of this information is, once more, structured in JSON with strings that represent keys ("user-agent","from") and values ("Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3325.162 Safari/537.36","Your name example@domain.com").
First, we can give the website owner information about the kind of user-agent ① we’re using. While this information is not necessary for bots, it may allow your scraper to open websites that normally can’t be opened outside of a web browser. Your scraper can also use the different browsers your computer already has installed to access websites. The user-agent header can communicate information about the browser capabilities our bot might use to open a page within a browser (in this example we don’t do this, but this may be a useful habit to adopt early on when you write other bots). To find out what other user-agents you use, you can find various online tools, including one here: https://www.whoishostingthis.com/tools/user-agent/.
Then we can specify who we are ② within a string assigned to the key from. In this case, you can write your name and an email address into the string to serve as your contact information. To use these headers, we assign them to the headers parameter in the requests.get() ③ function.
Last but not least, we should also avoid overburdening the servers that host the websites we are scraping. As mentioned earlier, this often happens when a scraper opens multiple pages in rapid succession without taking a break between each request.
For that purpose we can use a library called time, which is part of Python’s standard library, so it’s already installed. Add the code from Listing 5-15 to your script.
--snip--
# Import our libraries that we will need to scrape a website
import csv
import time①
from bs4 import BeautifulSoup
import requests
time.sleep(2)②
Listing 5-15: Adding pauses in the scraper’s code
To use the time library, first we need to import it ①. Then, we can use a function from it called sleep() ②, which basically tells our scraper to take a break. The sleep() function takes a number as an argument—an integer (whole number) or float (number with decimals)—which represents the amount of time, measured in seconds, for the break. In line ②, our script is instructed to wait for 2 seconds before resuming and scraping data.
If we now stitch together all of the code snippets we’ve written throughout this chapter, our script should look like Listing 5-16.
# Import our modules or packages that we will need to scrape a website
import csv
import time
from bs4 import BeautifulSoup
import requests
# Your identification
headers = {"user-agent" : "Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/41.0.2228.0 Safari/537.36;",
"from": "Your name <example@domain.com>"}
# make an empty array for your data
rows = []
# open the website
urls = ["https://en.wikipedia.org/wiki/Category:American_women_computer_scientists", "https://en.wikipedia.org/w/index.php?title=Category:American_women_computer_scientists&pagefrom=Lehnert%2C+Wendy%0AWendy+Lehnert#mw-pages"]
def scrape_content(url):
time.sleep(2)
page = requests.get(url, headers= headers)
page_content = page.content
# parse the page through the BeautifulSoup library
soup = BeautifulSoup(page_content, "html.parser")
content = soup.find("div", class_="mw-category")
all_groupings = content.find_all("div", class_="mw-category-group")
for grouping in all_groupings:
names_list = grouping.find("ul")
category = grouping.find("h3").get_text()
alphabetical_names = names_list.find_all("li")
for alphabetical_name in alphabetical_names:
# get the name
name = alphabetical_name.text
# get the link
anchortag = alphabetical_name.find("a",href=True)
link = anchortag["href"]
# get the letter
letter_name = category
# make a data dictionary that will be written into the csv
row = { "name": name,
"link": link,
"letter_name": letter_name}
rows.append(row)
for url in urls:
scrape_content(url)
# make a new csv into which we will write all the rows
with open("all-women-computer-scientists.csv", "w+") as csvfile:
# these are the header names:
fieldnames = ["name", "link", "letter_name"]
# this creates your csv
writer = csv.DictWriter(csvfile, fieldnames=fieldnames)
# this writes in the first row, which are the headers
writer.writeheader()
# this loops through your rows (the array you set at the beginning and have updated throughtout)
for row in rows:
# this takes each row and writes it into your csv
writer.writerow(row)
Listing 5-16: The completed scraper script
To run and test your scraper, make sure you are connected to the internet and save your file. Open up your command-line interface (CLI), navigate to the folder that contains the file, and then run one of the following commands in your CLI based on the version of Python you’re using. On Mac, use this command:
python3 wikipediascraper.py
On a Windows machine, use this command:
python wikipediascraper.py
This should produce a .csv file in the folder that contains your wikipediascraper.py file.
Summary
All in all, these practices have taught you not only the power of scraping but also the ethical ramifications that your actions may have. Just because you have the capability to do something does not always mean you have free rein to do so. After reading this chapter, you should have all the knowledge you need to gather data responsibly.
Happy scraping!